Poster Sessions Provoke Deep Discussions at the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
By Lori Cameron
By Lori Cameron on
 Long Beach, California—The 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) saw its largest gathering of professionals from across the world and from the furthest reaches of the computer vision, machine learning, and artificial intelligence industries. This year's conference had a record-breaking 9,000+ in attendance and a whopping 181 exhibitors including big names like Microsoft, Amazon, Apple, Facebook, Google, IBM, Hauwei, and Tencent.
Long Beach, California—The 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) saw its largest gathering of professionals from across the world and from the furthest reaches of the computer vision, machine learning, and artificial intelligence industries. This year's conference had a record-breaking 9,000+ in attendance and a whopping 181 exhibitors including big names like Microsoft, Amazon, Apple, Facebook, Google, IBM, Hauwei, and Tencent.
Hundreds of posters were on display in the exhibit hall representing fast illustrations of scientific research with the intent of stimulating interest and discussion.
Here's how it worked.
Everyone whose paper was accepted at the conference was given the opportunity to convert their paper into a poster—a corresponding, visually-appealing summary of their research. In turn, a smaller percentage of authors were given a chance to present their papers orally.
The sheer magnitude of knowledge being shared and high level of technical expertise was evident everywhere.
But for all the deep discussions that went on at this conference, the poster presentations provided the most robust form of one-on-one conversation with researchers about their work. The sessions allowed attendees the chance for intense engagement with the brightest minds in the field.
So, who browsed these provocative posters?
Nearly half of all attendees came from industry, while the remaining attendees hailed from academia and elsewhere. The top three fields represented were manufacturing, services, and education. Nearly a third of all attendees came from companies with 10,000 employees or more. Sixty-three percent of attendees were between the ages of 18 and 34.
Poster Session Highlights from the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition

Jonathan Barron of Google Research is mobbed by curious onlookers as he expounds on his poster presentation "A General and Adaptive Robust Loss Function."
"By introducing robustness as a continuous parameter, our loss function allows algorithms built around robust loss minimization to be generalized, which improves performance on basic vision tasks such as registration and clustering," says Barron.

Need braces? Zhiming Cui of the University of Hong Kong describes new research to improve orthodontic care in his poster titled "ToothNet: Automatic Tooth Instance Segmentation and Identification from Cone Beam CT Images."
"To the best of our knowledge, our method is the first to use neural networks to achieve automatic tooth segmentation and identification from CBCT images," says Cui and his co-authors Changjian Li and Wenping Wang.
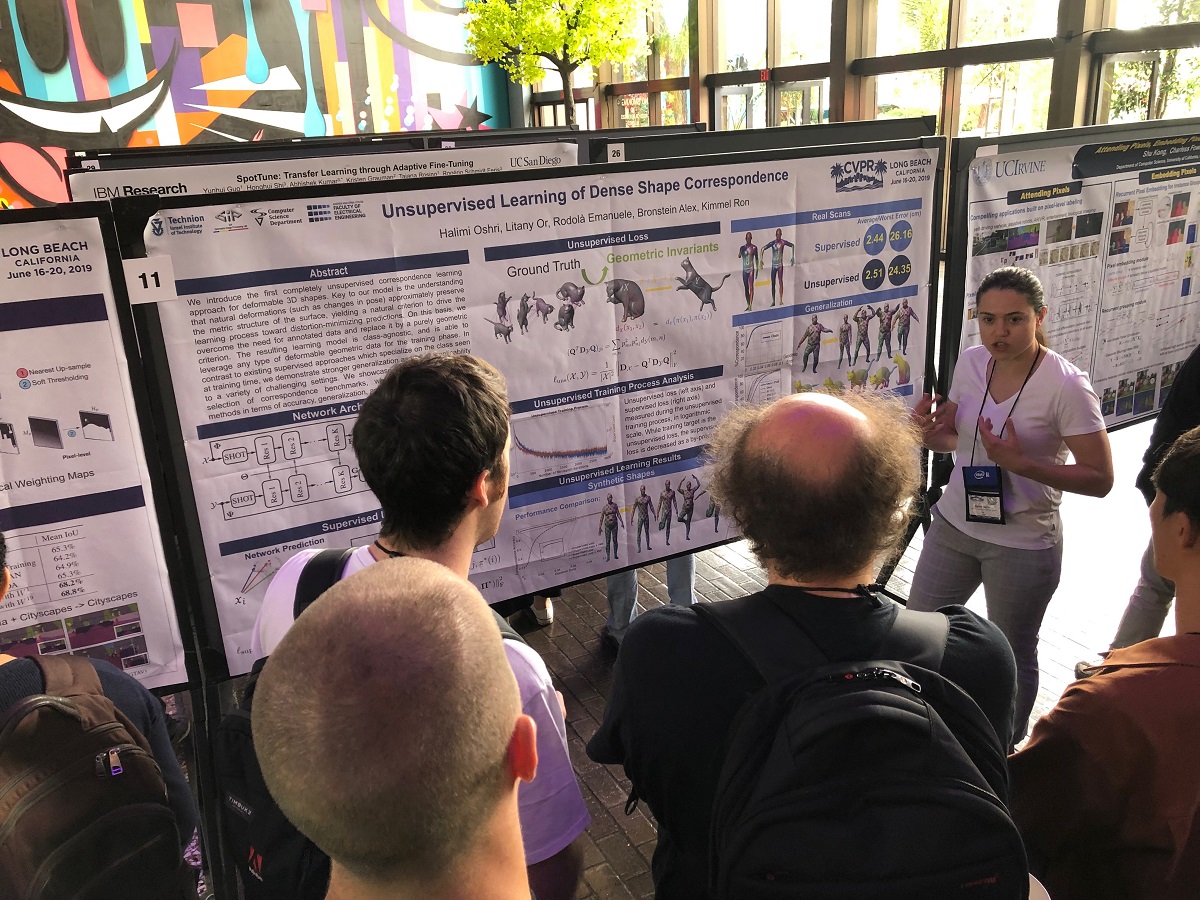
Halimi Oshri of Technion, Israel Institute of Technology explains the innovative concept behind her poster titled "Unsupervised Learning of Dense Shape Correspondence."

"We introduce the first completely unsupervised correspondence learning approach for deformable 3D shapes. Key to our model is the understanding that natural deformations (such as changes in pose) approximately preserve the metric structure of the surface, yielding a natural criterion to drive the learning process toward distortion-minimizing predictions.
"On this basis, we overcome the need for annotated data and replace it by a purely geometric criterion," says Oshri and her co-authors Or Litany, Emanuele Rodola, Alex M. Bronstein, and Ron Kimmel.
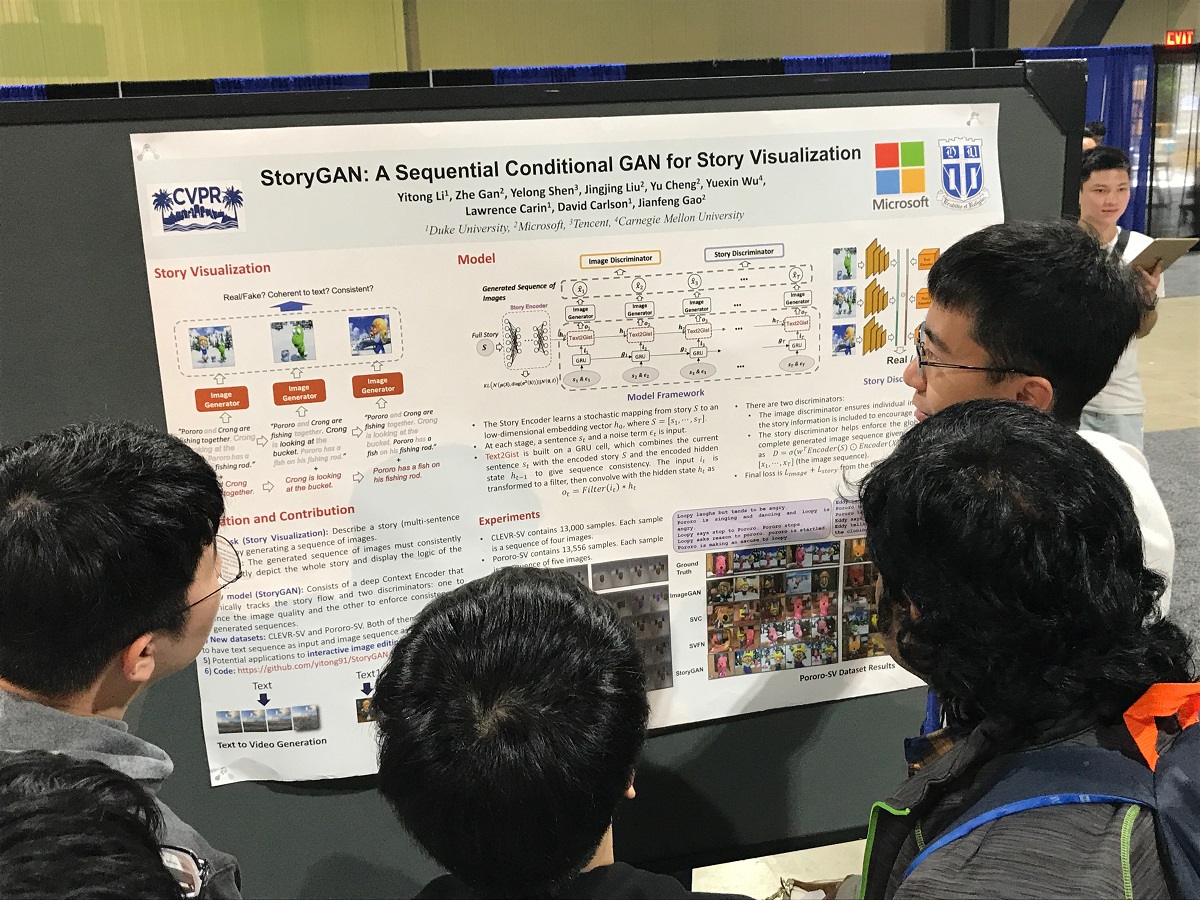
Yitong Li of Duke University explains the concept behind "StoryGAN: A Sequential Conditional GAN for Story Visualization," which is to generate images that correspond with each sentence in a paragraph for enhanced storytelling.
"Our model is unique in that it consists of a deep Context Encoder that dynamically tracks the story flow, and two discriminators at the story and image levels, to enhance the image quality and the consistency of the generated sequences," says Li and his co-authors Zhe Gan, Yelong Shen, Jingjing Liu, Yu Cheng, Yuexin Wu, Lawrence Carin, David Carlson, and Jianfeng Gao.
The research team hails from Duke, Microsoft, Tencent, and Carnegie Mellon University.
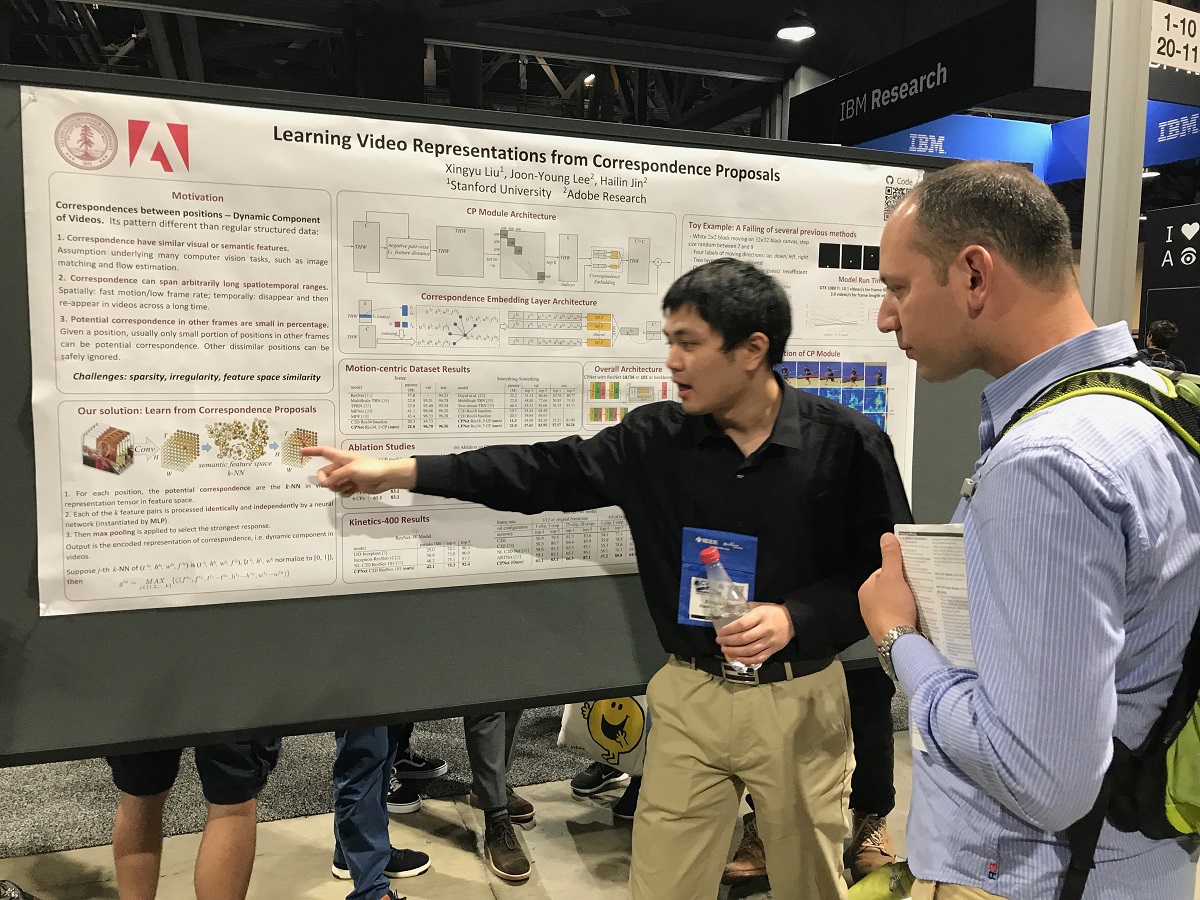
Xingyu Liu of Stanford University explains the finer points of his poster "Learning Video Representations from Correspondence Proposals."
"We propose a novel neural network that learns video representations by aggregating information from potential correspondences," say Liu and his co-authors Joon-Young Lee and Hailin Jin, both from Adobe Research.

Chenliang Xu of the University of Rochester poses with the "Hierarchical Cross-Modal Talking Face Generation with Dynamic Pixel-Wise Loss" poster created by him and his research team.

Lele Chen of the University of Rochester explains the "talking face" generator, which is capable of using a still photograph of a person and an audio recording of their voice to create a video of their face articulating the words of the recording. Although it has yet to be perfected, the technology can eventually be used for language acquisition and cartoon creation!

The poster sessions were bustling and crowded. The conversations were animated and inquisitive.
Despite the bustle, conference attendees were courteous and respectful as they navigated the displays and talked to the experts.

This year's conference was held at the Long Beach Convention Center in Long Beach, California, on 16-20 June 2019.
Read more related articles about CVPR:
- How CVPR 2019 Conference -- Tech's Premier Event for Computer Vision -- Broke Records on All Fronts. Cite Self-Driving Cars and Your Social Media Apps, says Finance Co-Chair Walter Scheirer
- Oral Presentations of Papers at the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
- Opening Remarks and Awards of the Record-Breaking 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
- Industry Exhibitors Take Over Hundreds of Thousands of Square Feet at the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
- Tutorials Detail Advances in Robotics, AR/VR, and Self-Driving Cars at the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
- Workshops of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)

About Lori Cameron
Lori Cameron is Senior Writer for IEEE Computer Society publications and digital media platforms with over 20 years of technical writing experience. She is a part-time English professor and winner of two 2018 LA Press Club Awards. Contact her at l.cameron@computer.org. Follow her on LinkedIn.







