How Netflix Adopted the New Mindset of Software Failure as the Rule—Not the Exception—and Survived the Great 2015 Amazon Web Services Outage
By Lori Cameron

On September 20, 2015, Amazon Web Services experienced an outage that ripped through its cloud database services, affecting many well-established, tech savvy companies and costing them several hours of operation.
Except Netflix.
The entertainment giant experienced just a few minutes of downtime before they were up and running again. Their secret is a set of testing tools called the Netflix Simian Army that runs simulated outages and system failures before the real ones hit.
Why Netflix survived the outage is a case study in how digital solutions need a new way of thinking: Failure, or change, is the rule, not the exception. And it's a wise company that runs experiments simulating failure, says new research.
"Writing software for the cloud demands that we treat change as the rule, rather than the exception. It is this that allows us to produce software that runs more reliably than the infrastructure that it is deployed to," writes Cornelia Davis, senior director of technology at Pivotal, and author of "Realizing Software Reliability in the Face of Infrastructure Instability," (login may be required for full text) which appears in the September/October 2017 issue of IEEE Cloud Computing.
The vanguard of this new mindset, Netflix Simian Army, is a barrel of monkeys—seriously.
"Chaos Kong is one part of a suite of tools Netflix has built to test their software’s operation in the event of outages of the infrastructure that it runs on. Different testing tools that make up the Netflix Simian Army are cast against different failure domains. Chaos Kong simulates region outages. Chaos Gorilla simulates availability zone failures. Chaos Monkey actually kills servers," writes Davis.
How does the system work?
Netflix designs for failure
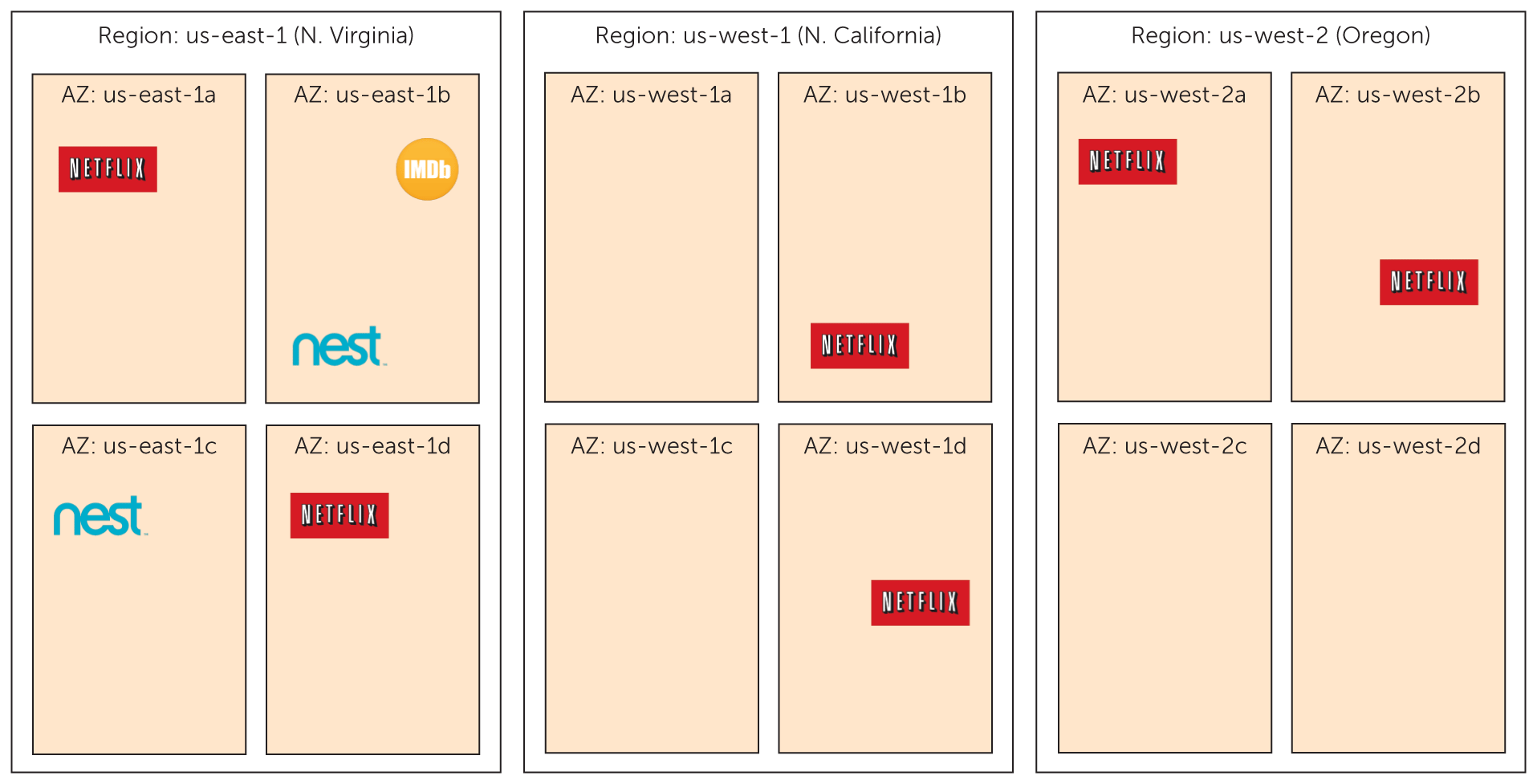
Companies that use cloud services need to expect outages and service failures.
"Over the last several decades we’ve seen ample evidence that an operational model that is predicated on a belief that our environment changes only when we intentionally and knowingly initiate such changes simply doesn’t work. Reacting to unexpected changes dominates time spent by IT and traditional software development lifecycle processes that depend on estimates and predictions have proven problematic," writes Davis.
Netflix incorporates redundancy
Not everything will work all of the time.
"No single system can be guaranteed to be functional 100% of the time and as we’ve just concluded, redundancy is essential to surviving the inevitable failures. When deploying into these cloud environments, the trick, however, is to ensure that your redundancy spans failure boundaries—if all of your redundant app instances are running on the same host and that host goes down, the redundancy serves no purpose," Davis says.
Netflix tests for weaknesses during production
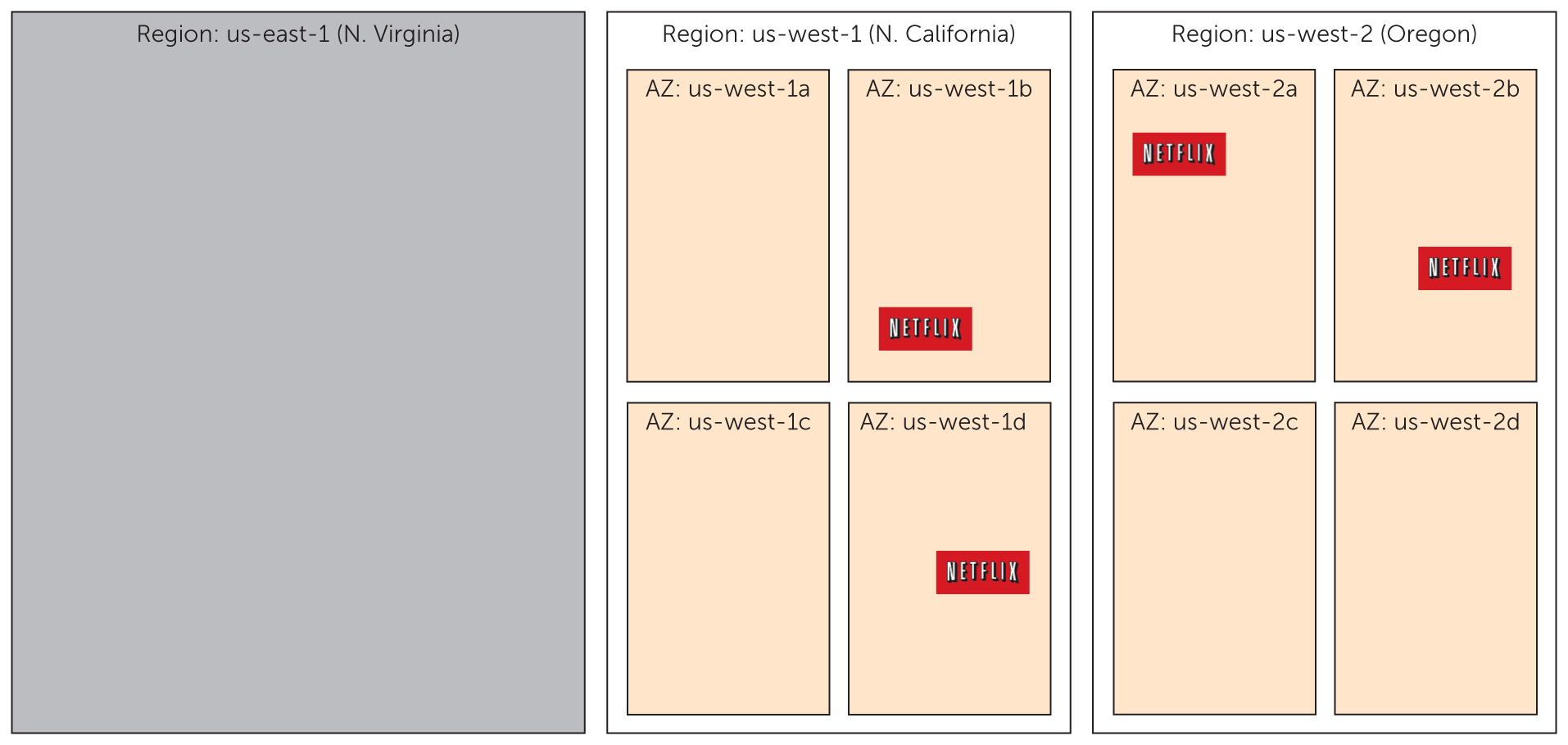
"Use of automated testing as a part of the SDLC (traditional software development lifecycle) is becoming fairly pervasive in the industry, with many organizations going so far as to practice test-driven development where they write the tests even before the implementation. And while there is no debate as to the value of a test suite that primarily focuses on expected inputs and outputs, a new practice has emerged in the last few years, and it not a coincidence that the heroes of our story have been at the forefront of innovation in this space," says Davis.
It wasn’t always the way things were done.
"I am suggesting that you experiment in production. Twenty years ago, this would have been considered insane, but the born-in-the-cloud software companies like Facebook, Twitter, Google, and Netflix have shown that it works," Davis added.
As a result, the movies streamed into your living room have run smoothly enough—despite the unfortunate 2015 outage.
"This is not attributed to luck, rather, Netflix deeply understands what it means to run software in the cloud," Davis said. "They recognize that the software architectures of the last decades do not work well in the cloud, an environment that is constantly changing and is more distributed than ever before."
For its part, Amazon Web Services ran an explanation and an apology for the 2015 blackout.
The ultimate goal is to create a reliable internal system even if the cloud service system being used is unpredictable.
"Ultimately our aim is to provide reliable digital solutions even while the infrastructure they are running on is unstable," says Davis.
Research related to cloud infrastructure in the Computer Society Digital Library:
- Infrastructure as a Service and Cloud Technologies
- Toward a Global Data Infrastructure
- Integrating Smartphones into the SmartSantander Infrastructure
- Smart Infrastructure Design for Smart Cities
- Minimizing and Managing Cloud Failures

About Lori Cameron
Lori Cameron is a Senior Writer for the IEEE Computer Society and currently writes regular features for Computer magazine, Computing Edge, and the Computing Now and Magazine Roundup websites. Contact her at l.cameron@computer.org. Follow her on LinkedIn.







