An Antidote to "Too Long; Didn't Read": Automatic Pictures Beside those Long Blocks of Text Will Cure tl;dr
By Lori Cameron
By Lori Cameron on
 We all know that Internet experience: Too long, didn't read (except for this article), or tl;dr for short.
The hard fact is, busy people simply don’t have the time to read great big walls of uninterrupted text. Others struggle to make connections without images. Media experts know that you can lose readers if you don’t blend text with images. In fact, Evening Journal editor Arthur Brisbane crafted a now-popular maxim in 1911 when he told members of the Syracuse Advertising Men’s Club to "use a picture. It’s worth a thousand words."
That's why researchers are developing applications that will automatically add pictures to text so that readers can determine if it’s worth their time.
"Readers of business reports, newspapers, and social media face the challenge of interpreting large volumes of text in a short amount of time. Further, information loss can be experienced by people who have trouble with text-only documents, those using hand-held devices, and those who might not be able take in written material at a standard pace," write J. Kent Poots of York University and Ebrahim Bagheri of Ryerson University in their IT Professional article "Automatic Annotation of Text with Pictures." (login may be required for full text)
We all know that Internet experience: Too long, didn't read (except for this article), or tl;dr for short.
The hard fact is, busy people simply don’t have the time to read great big walls of uninterrupted text. Others struggle to make connections without images. Media experts know that you can lose readers if you don’t blend text with images. In fact, Evening Journal editor Arthur Brisbane crafted a now-popular maxim in 1911 when he told members of the Syracuse Advertising Men’s Club to "use a picture. It’s worth a thousand words."
That's why researchers are developing applications that will automatically add pictures to text so that readers can determine if it’s worth their time.
"Readers of business reports, newspapers, and social media face the challenge of interpreting large volumes of text in a short amount of time. Further, information loss can be experienced by people who have trouble with text-only documents, those using hand-held devices, and those who might not be able take in written material at a standard pace," write J. Kent Poots of York University and Ebrahim Bagheri of Ryerson University in their IT Professional article "Automatic Annotation of Text with Pictures." (login may be required for full text)
Ebrahim Bagheri, PhD, P.Eng., was honored at the 2016 Ontario Professional Engineers Awards gala with the Engineering Medal for Young Engineer.
Examples of picturing text technology
Poots and Bagheri analyzed a number of applications, such as WordsEye, that match text with images, to see how well they worked. "To tackle the challenge of interpreting text and to help breach the ‘information-assimilation wall’ of cognitively deficient readers, a novel application has emerged that automatically adds pictures to text. This application is called automatic text annotation with pictures, concept picturing, or text picturing. The objective is to reduce a reader’s cognitive information processing load by showing relevant pictures along with input text. A reader can quickly and easily decide if the text information deserves a closer look," they say.

Four screenshots from WordsEye’s artistic gallery of user scenes
Text annotation with pictures can be used in a variety of contexts including the classroom, reports, advertising, news, and social media. It can also be used to help people who speak other languages or are unable to use verbal speech to communicate. "For writers, bloggers, and editors, linking text with media content is crucial. Visual content helps readers follow the crux of a discussion or identify the core theme of an article. In efforts to organize and display helpful images, content managers, news writers, and user-interface designers perform page layout, assigning images to concepts," say the authors.How "automatic text annotation with pictures" works
In simplest terms, the application involves matching text with tagged images in a library or collection. But knowledge extraction and labeling takes a lot of work—at least, it used to. "Knowledge extraction presents the primary set of technical challenges. For this purpose, knowledge can be extracted using distributional techniques (such as named entity extraction), using linguistic techniques (like ontology-assisted knowledge extraction) or a hybrid approach. Knowledge extraction using distributional techniques requires sizable collections of labeled examples and statistical analysis tools, along with hours of hand-labeling effort," the authors say. Now, computer applications are changing that. "With the evolution of computing capability, the required statistical analysis tools are now within reach of researchers. This was not the case even 10 years ago. Linguistic tools have also evolved to the point where off-the-shelf components (such as those for parsing) can be used in the text analysis pipeline," say the authors.Three levels of language input
The text with which you want to match an image can be analyzed on three levels: paragraph, sentence, and word. In the image below, you can see how different the image output is when you do word-level picturing for "Victoria" (a) as opposed to sentence-level picturing for "People from Canada celebrate the birthday of Queen Victoria" (b). "Sentence-level resolution gives context for a collection of words, allowing identification of relationships. Figure 1b shows multiple concepts related to Queen Victoria’s birthday," say the authors.
"Sentence-level resolution gives context for a collection of words, allowing identification of relationships. Figure 1b shows multiple concepts related to Queen Victoria’s birthday," say the authors.
Knowledge resources for text and images
Knowledge resources are external sources that help clarify meaning. Text resources like Wikipedia and WordNet (a popular database where words are grouped according to their semantic relationships) are used to clarify the meaning of the original text. Image resources like Flickr, which uses tags, and Wikimedia, which uses "infoboxes," can be retrieved by software applications. There are also more highly specialized image databases out there. "The web offers collections of domain-specific images that can be used for text annotation. For instance, medicine is represented by databases containing medical images, such as X-rays (see the Centers for Disease Control Image Library, while business sector topics are represented by more generic commercial databases such as Shutterstock," the authors say.Matching pictures to text
The text can be analyzed for graphs, statistics, key phrases, and key words. It can also be analyzed for grammar. "In the sentence ‘John ate the red apple,’ grammar rules say that the subject is John, the action (or predicate) is ate, and the object (or target of the action) is the red apple. The knowledge we can extract is who (John) did what (ate) to whom or what (the red apple). Then we can use this to find appropriate images," say the authors. The words and concepts found in the text are then matched with words and concepts tied to database images. "Image descriptions can come from four sources: URLs, surrounding text, user tags, and analysis of visual content. 16 An example of matching for ‘John ate a red apple’ would be a picture of a man (picture tags ‘man’ and ‘human’), a picture of someone eating food (picture tags ‘person eating, ‘person,’ ‘hungry’), and a picture of an apple," the authors say. But how many images will this produce? Three separate images or one? The number of images is not just determined by separate concepts but by a cohesive idea.
"One or more output scenes are created for each unit of linguistic input where the number of output scenes is determined by the number of input text concepts. Rather than assemble a scene from several images, it is possible to find images that illustrate multiple concepts, perhaps "man eating (an) apple." These complex images could be used as the entire output scene," write the authors.
But how many images will this produce? Three separate images or one? The number of images is not just determined by separate concepts but by a cohesive idea.
"One or more output scenes are created for each unit of linguistic input where the number of output scenes is determined by the number of input text concepts. Rather than assemble a scene from several images, it is possible to find images that illustrate multiple concepts, perhaps "man eating (an) apple." These complex images could be used as the entire output scene," write the authors.
Analysis of eight well-known picturing technologies
The authors analyzed eight well-known text picturing technologies to learn how they function. In the table below, they detail the most notable features about each of the technologies: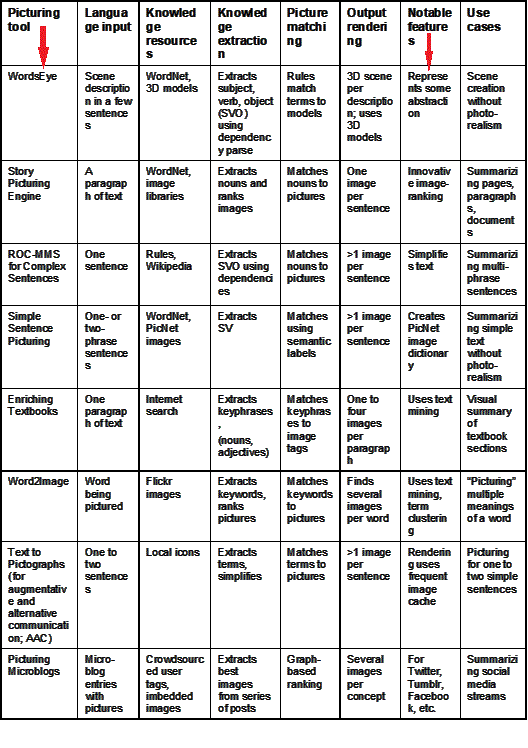
Related research on computer graphics and text analysis in the Computer Society Digital Library
Login may be required for full text.- Quality Assessment and Perception in Computer Graphics
- Topic- and Time-Oriented Visual Text Analysis
- Next-Generation Text Entry
- A Computer Graphics Back-to-School Special
- Lexicon Generation for Emotion Detection from Text
- Text Analytics for Predicting Question Acceptance Rates
 About Lori Cameron
Lori Cameron is a Senior Writer for the IEEE Computer Society and currently writes regular features for Computer magazine, Computing Edge, and the Computing Now and Magazine Roundup websites. Contact her at l.cameron@computer.org. Follow her on LinkedIn.
About Lori Cameron
Lori Cameron is a Senior Writer for the IEEE Computer Society and currently writes regular features for Computer magazine, Computing Edge, and the Computing Now and Magazine Roundup websites. Contact her at l.cameron@computer.org. Follow her on LinkedIn.






