Chaos Engineering: It sounds scary, but intentionally harming systems can find bigger bugs. How to make the cultural shift, from Netflix experts who do it.
By Lori Cameron
By Lori Cameron on
 No good employee throws a monkey wrench into the works, but that's exactly what chaos engineers do: They deliberately create small problems in their software systems and fix them before they become big.
They admittedly flirt with danger—but only to size up bigger potential failures.
"By running chaos experiments directly on a production system in a controlled manner, you can improve your system’s availability by identifying and eliminating problems before they manifest as outages," says a team of senior software and chaos engineers at Netflix in "The Business Case for Chaos Engineering" in IEEE Cloud Computing.
Serious tech companies should adopt such practices, the Netflix engineers assert.
No good employee throws a monkey wrench into the works, but that's exactly what chaos engineers do: They deliberately create small problems in their software systems and fix them before they become big.
They admittedly flirt with danger—but only to size up bigger potential failures.
"By running chaos experiments directly on a production system in a controlled manner, you can improve your system’s availability by identifying and eliminating problems before they manifest as outages," says a team of senior software and chaos engineers at Netflix in "The Business Case for Chaos Engineering" in IEEE Cloud Computing.
Serious tech companies should adopt such practices, the Netflix engineers assert.
One of the authors, Nora Jones, describes why we need more chaos—chaos engineering, that is.
The stakes are high. Just ask the Knight Capital Group, a U.S. trading firm that lost over $400 million in 2012 because of a software configuration problem. If chaos engineers had tested the program ahead of time, perhaps the loss might have been avoided. And it's not just money. In some domains such as transportation, broken systems can result in lost lives. Read how Netflix avoided the 2015 outage that ripped through Amazon Web Services.Chaos Engineering 'may require a cultural shift'
The video streaming giant knows, however, that chaos engineering can be a hard sell to corporate executives. "This type of experimentation requires a technical shift within the organization. If applications were not originally designed to support chaos experiments, engineers must incorporate new tooling such as fault injection and guard rails to minimize blast radius," write the Netflix engineers. "More importantly, Chaos Engineering may require a cultural shift. In doing so, a successful program can change the way software engineers build systems by creating incentives for resilient design," they say. "Chaos Engineering sounds dangerous ('you want to intentionally cause problems in the production system?'), so you’ll need to make the case to your organization that a chaos program is worthwhile," they add.Josh Evans, former director of operations engineering at Netflix, talks about the chaotic and vibrant world of microservices at Netflix.
So, if you want to sell your company on the idea of chaos engineering, the Netflix team has some tips for you.Minimizing the 'blast radius'
Your company might balk at the idea of trying to damage their systems, but the payoff from chaos engineering can be huge. Teams can and should manage the extent to which a system suffers from chaos experiments. Read about Netflix's newest chaos tool: Chaos Automation Platform (ChAP) "Regardless of the level of impact, it’s important to have safety features with chaos experiments that minimize blast radius. Experimenting in production has the potential to cause unnecessary customer pain. While there must be an allowance for some short-term negative impact, it is the responsibility and obligation of the chaos engineering team to ensure the fallout from experiments is minimized and contained," the authors say. Containing the malfunction radius means chaos engineering is not as chaotic as you might think. Measured attacks on a system can be controlled, reducing the extent of damage. "In forest management, controlled burning is used in cooler months to prevent devastating forest fires in hotter and dryer times of the year. In the same way, controlled chaos experiments can uncover vulnerabilities that would otherwise cause significant damage," the authors say.Cost-benefit analysis of 'intentionally inducing harm'
A chaos engineering program has two first-order costs. The first is the engineering team. Netflix’s chaos engineering team is made up of four full-time software engineers.
 The Netflix team then created their own ROI example to illustrate how the equation works:
The Netflix team then created their own ROI example to illustrate how the equation works:

Need for storytelling
Science and money aren't enough in convincing employers to hire chaos teams. You need to be artful, too. "Even if you can demonstrate positive ROI, you’ll need to make a qualitative argument, tell a good story, to make an effective case for chaos," says the Netflix team. Consider how they found one problem and then created a narrative to remedy it. "When Netflix moved out of the data center and into the cloud, engineers quickly learned about the perilous properties of the cloud: commodity-grade hardware combined with a scale-out approach where scale is achieved by adding more servers. The result was that, in the cloud, servers were more likely to disappear, leaving subscribers without service and our engineers scrambling in the middle of the night to restore the service," they say. They gave their solution a whimsical name. "That’s when we created Chaos Monkey. Chaos Monkey randomly terminates production server instances during business hours, when engineers are available to track and fix issues. This quickly uncovered many of our vulnerabilities to instance terminations, making our service resilient to this class of failures. "For example, there was a hand-patched “snowflake” server that was responsible for synchronizing some DNS configuration. When Chaos Monkey terminated the server, Amazon replaced it with a server that did not have the hand-patched settings, which resulted in an incident," say the authors. Read more about Netflix's 'barrel of monkeys'Understand what your critical services are
At Netflix, the main critical service is video playback—a tier 1 service. They also offer movie suggestions, but that service is not critical to video playback—hence, a tier 2 service. Each company can build its own chart of service tiers similar to the one Netflix created for itself (below):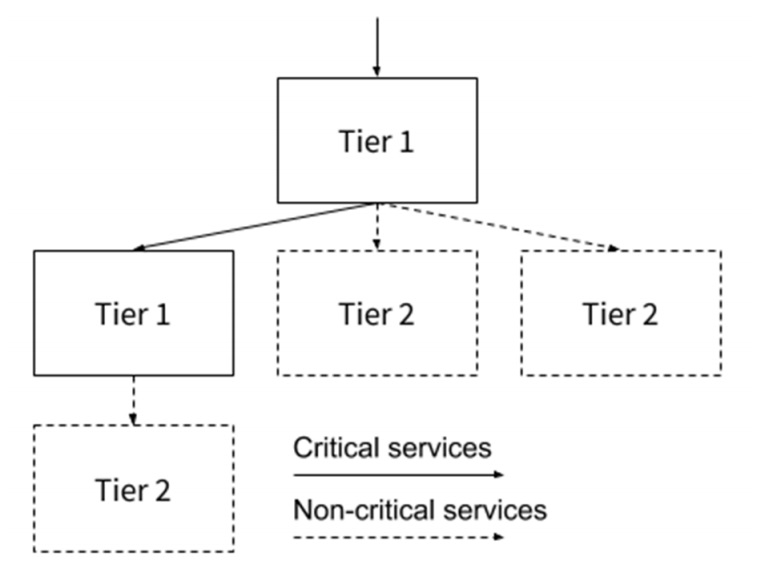
Run tests 'in the small' and 'in the big'
The real test of chaos engineering is whether or not the fixes work throughout the company's entire system. "Like all software, these mechanisms can be independently tested in the small via unit tests to ensure they function as desired. However, the true test of these strategies is to see how they react in a production environment under load, particularly when you consider that each one requires tuning and configuration to set boundary conditions," the authors say. The implication is that, once tests are run with success in a limited part of the system ("in the small"), it must be run "in the big"—or through the whole system to determine how robust it is.Deciding when and how much chaos engineering to do
Normally, testing occurs whenever there is a change to the system. Chaos engineers need to balance testing against the frequency with which customers will have a bad experience online. "At Netflix, there are tools like Chaos Monkey that run all the time in production and they have become part of the engineering culture. As we dive into more large-scale types of testing, we are more cautious, yet the frequency has increased over the last few years," the authors say. The team says that, as your company's chaos engineering system evolves, it should become more automated. Eventually, it should take over more of the process. "Once you feel comfortable teams have an understanding and involvement in the chaos engineering practice, begin to remove yourself from the equation and allow the tool to handle more and more of the responsibilities," say the authors.Closing pitch
The Netflix team is aware of upper management's skepticism about the new field. They invite peers to leverage the Netflix experience when developing their own pitches to the C-suite. "By telling a story around the benefits of chaos realized at organizations such as Netflix, and by making quantitative arguments based on your historical data, you should be able to make a strong case that introducing chaos engineering will yield real, tangible benefits to the business," they say.What to do next if your company likes the idea of chaos engineering
Celebrate, of course. Then, determine the success criteria for your company by answering three questions:- What are our business goals? (In most cases, these center around attracting and keeping customers.)
- What are our key performance indicators (KPIs)? (For an ecommerce company, a KPI might be the number of customers checking out, searching for an item, or adding an item to a shopping basket.)
- What is the cost of impact to service availability? (These could include the cost of acquiring a customer, a safety impact, the engineering hours spent resolving the issue, or phone calls to your customer service team.)
- Chaos Engineering
- The Power to Create Chaos
- Reliability Engineering
- Software Engineering (by Bruce McMillin)
- Software Engineering (by Rick Kazman)
 About Lori Cameron
Lori Cameron is a Senior Writer for the IEEE Computer Society and currently writes regular features for Computer magazine, Computing Edge, and the Computing Now and Magazine Roundup websites. Contact her at l.cameron@computer.org. Follow her on LinkedIn.
About Lori Cameron
Lori Cameron is a Senior Writer for the IEEE Computer Society and currently writes regular features for Computer magazine, Computing Edge, and the Computing Now and Magazine Roundup websites. Contact her at l.cameron@computer.org. Follow her on LinkedIn.






