Fighting Human Traffickers: An AI Tool is Created to "DIG" into Sex Rings and Decode Open Web Domains. More than 200 Law Agencies Now Use It.
By Lori Cameron
By Lori Cameron on

Human traffickers don't play by the rules. They use elaborate encryption and often post sex ads only once—changing phone numbers, names, and locations constantly, all in a bid to avoid detection.
But the tide is turning with a new investigative tool. It uses artificial intelligence algorithms primarily to scour open and, to a lesser extent, dark Web domains for human traffickers and decode their cloaked lingo selling sex slaves.
The developers call this technology "a real use-case of AI for Social Good," countering the doomsday fears held by some about artificial intelligence and proving itself unmatched in fighting online exploitation, the designers say in a new study.
What is the Domain Insight Graph, or DIG?
Researchers at the University of Southern California label their tool the "Domain Insight Graph (DIG) system,” an end-to-end investigative knowledge discovery system that scours the Web for digital breadcrumbs scattered in sex ads, allowing investigators to find victims and shut down sex rings.
The tool does many things: It's artificial intelligence, software, a search engine, and a builder of graphics and charts.
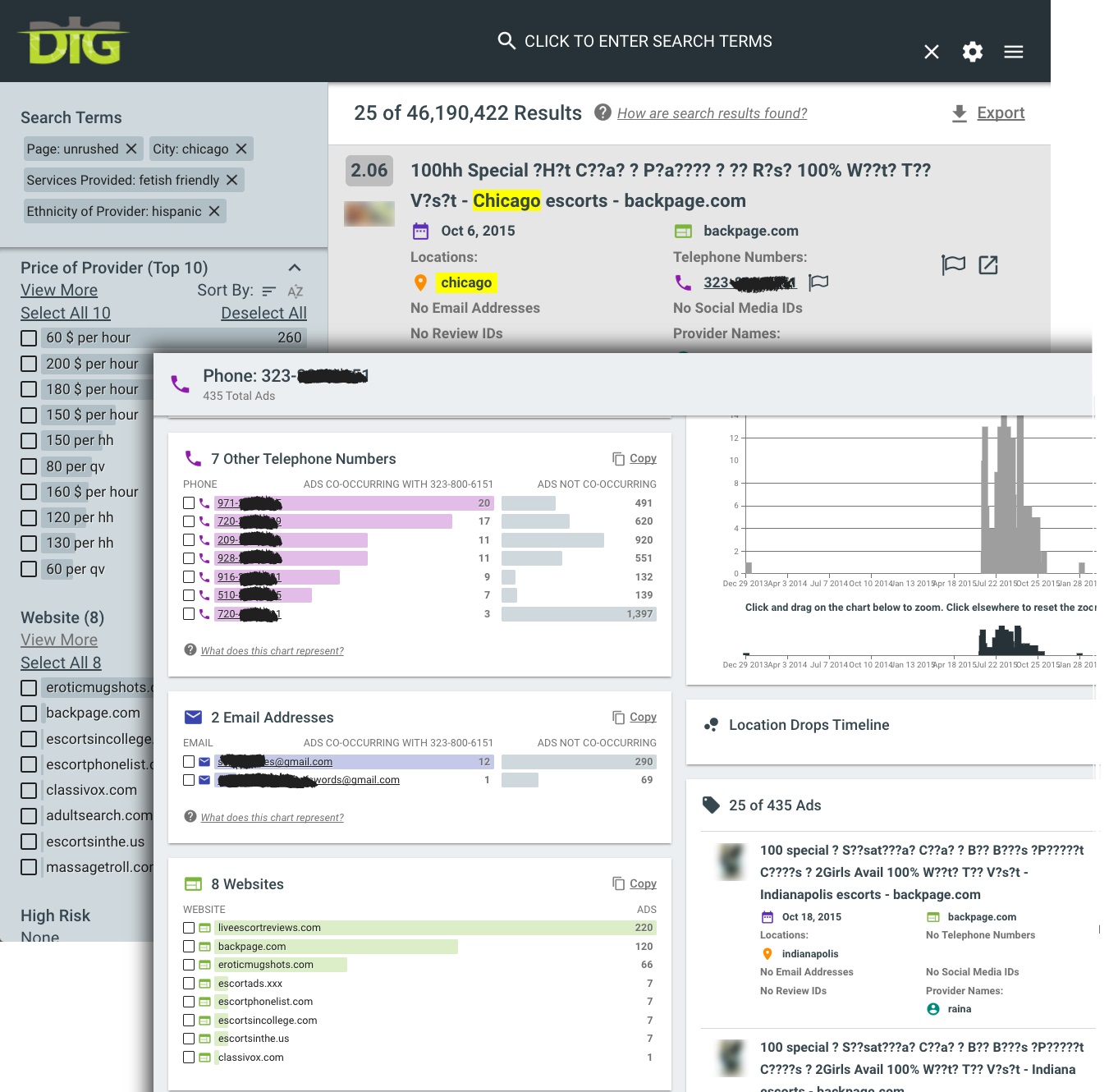
The system is so successful that it's now being used by over 200 law enforcement agencies around the country.
The Department of Defense is also experimenting with possibly using the tool for even broader investigations like securities fraud, narcotics, mail shipment fraud, counterfeit electronics, and illegal weapons sales.
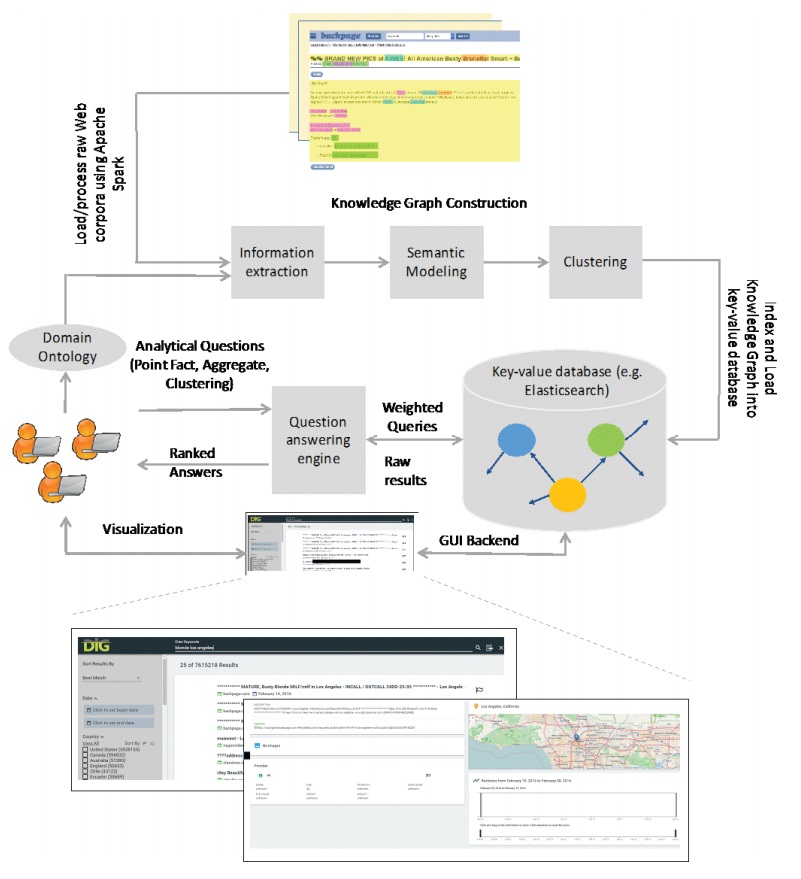
"We built and evaluated a prototype, involving separate components for information extraction, semantic modeling and query execution, on a real-world human trafficking Web corpus containing 1.3 million pages, with promising results," the authors say, referring to their early work. Those crawled pages have since grown to 25 million.
The results are encouraging.
"The system is ready for use in real-world operational scenarios involving point-fact and cluster queries," Mayank Kejriwal, Pedro Szekely, and Craig Knoblock in their research paper "Investigative Knowledge Discovery for Combating Illicit Activities." (login may be required for full text)
Mayank Kejriwal and Pedro Szekely describe the challenges of investigative search in the online sex trafficking domain, then demonstrate the Domain Insight Graph system that is currently being used by over 200 U.S. law enforcement officials.
"This task can largely be automated, allowing law enforcement to quickly query for, and uncover, latent ‘vendors’ providing human-trafficking services through advertisement of victims," they say.
The system, which got its first serious run during the four-week Human Trafficking Challenge organized by the DARPA MEMEX program in 2016, can be used beyond investigating criminals. It can also examine broader issues such as when criminal activity spikes and what ethnic groups of people are most likely to be exploited by human traffickers—information of great interest to social scientists.
"We note that the system can be used to support or refute certain hypotheses especially prevalent in popular imagination, such as whether human trafficking activity increases contemporaneously with events like the Super Bowl. Carefully designed studies can be used to also study the socio-ethnic impact of human trafficking by collecting statistics such as ethnicity extractions,” the researchers say.
"DIG"ging up sex traffickers and finding victims
Trafficking websites use advanced means of obfuscating data—excessive use of punctuation and special characters, and the presence of extraneous, hard-to-filter data such as embedded advertisements or artifacts in Web pages. Phone numbers aid tremendously in tracking victims, so traffickers use an especially maddening method of encrypting them.
"Consider, for example, the representative text fragment 'AVAILABLE NOW! ?? - (1 two 3) four 5 six - 7 8 nine 0 - 21.' Both the phone number (123-456-7890) and age (21) can be difficult to extract for named entity recognition tools trained on traditional text corpora,” say the authors.
But getting that phone number is important since it can be tied to multiple ads that reveal additional information such as name, email, and type of service—creating a "cluster" that can help identify a specific victim. Investigators can tighten the net even more by refining the search with other descriptions such as location, hair color, and ethnicity.
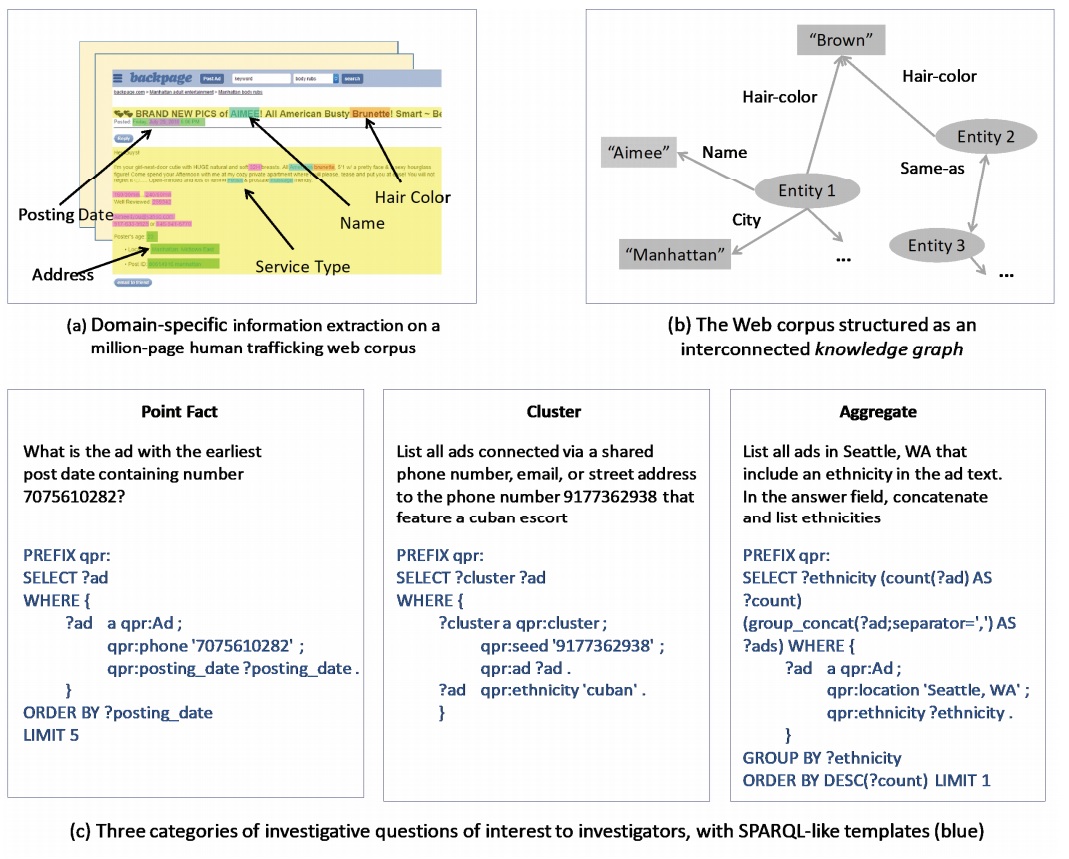
It's complicated but effective.
"Our approach takes as input raw webpages crawled over multiple Web domains and uses a composite set of tools, including high-recall information extraction (Figure a) and semantic typing, to structure the multi-domain corpus into a semi-structured knowledge graph (Figure b). Being high-recall, our knowledge graph construction approach is designed to handle illicit-field challenges such as information obfuscation without trivially degrading precision. A key contribution not included in the DIG KGC is a robust entity-centric search engine that permits investigators to pose analytical questions to the system from three categories, denoted here as point fact, cluster, and aggregate (Figure c)," say the authors.
How the DIG system differs from traditional search engines
Unlike Google, which has a one-size-fits-all search function, DIG helps investigators build a domain-specific search engine. All the different components, from collecting data to structuring and searching the knowledge, are geared towards supporting domain-specific needs.
Read related story about "Child Sexual Assault and Exploitation: How Detectives and Algorithm Engineers Partner to Catch Predators and Rescue Kids"
Another important feature of DIG is that anyone can use it, tech savvy or not. It's very different from other tools that require an army of developers—and almost always, an expensive license—to master and tune to particular needs. In some cases, a domain-specific search engine is entirely proprietary. For example, Yelp is a domain-specific search engine that contains review-based restaurant recommendations. However, it requires millions of dollars to build and maintain, and can't be used for other purposes such as investigating securities fraud or human trafficking.
In an era where complex tools such as deep learning toolkits abound—and there is a shortage of increasingly expensive data scientists—DIG offers an affordable tool to law enforcement who can't necessarily expend a lot of resources. In fact, the MEMEX program itself was instrumental in ensuring that the DIG program was accessible to all.
The last DARPA MEMEX workshop, held in Washington, D.C., last year, conducted inter-team reviews to ensure that systems and tools were usable by investigators with minimal skills in programming and data science.
Results of the DARPA MEMEX Human Trafficking Challenge 2016
So, what were the results of the DARPA MEMEX Human Trafficking Challenge back in 2016?
Quite good.
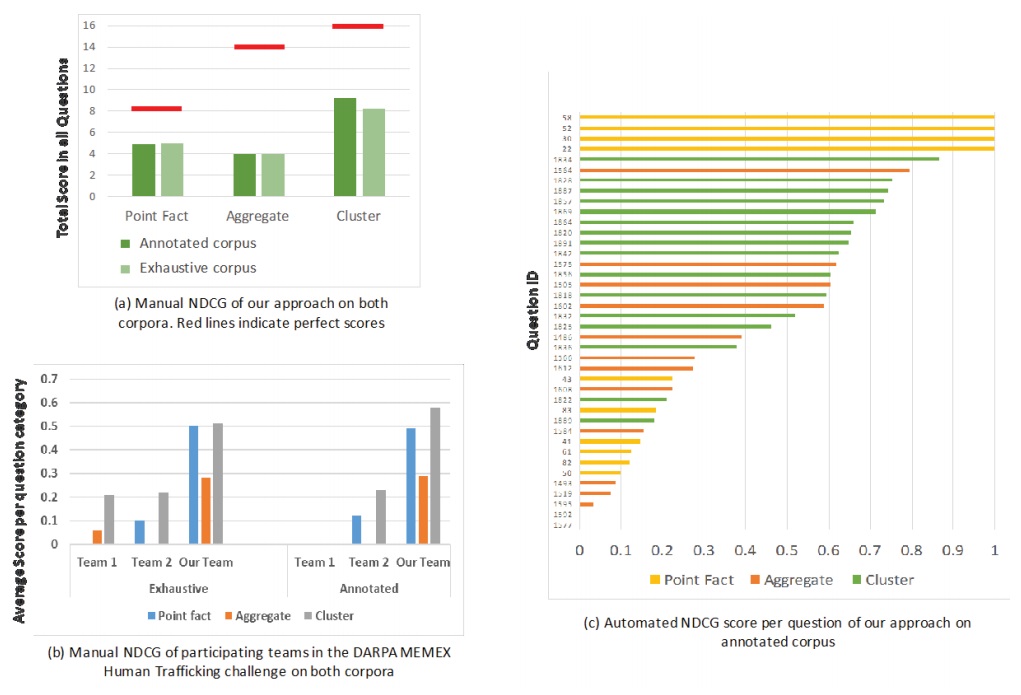
Team DIG scored the best relative performance (a) in the point-fact category.
They also beat out two other teams in the question category (b), which included point fact, aggregate, and cluster scores.
Answers to questions in the knowledge graph construction were also extremely reliable.
"A per-query result breakdown in Figure c illustrates the stability of our results. In other words, our scores are not skewed by a few well-performing queries. Nonzero scores (on the automated NDCG) are achieved for almost all queries. We believe that both high-recall knowledge graph construction, as well as robust question answering, contributed to these scores," the authors say.
Update on DIG research
In a recent interview, researcher Kejriwal explained how the DIG research has progressed in the aftermath of the 2016 DARPA MEMEX program:
- Law enforcement's feedback has been very positive, particularly from the office of the District Attorney of New York.
- DARPA might be able to use DIG for other types of investigations like securities fraud, narcotics, mail shipment fraud, counterfeit electronics, and illegal weapons sales.
- Kejriwal and his team have built a one-of-a-kind national online network of people forced into the sex trade from 25 million crawled sex ads.
- Social scientists can dig into the social network of online sex advertisers, discover how online sex rings grow, find sex rings concentrated in big cities, and find out what makes victims especially vulnerable to this crime.
- DIG (openly available under a permissive MIT license) now incorporates more advanced AI algorithms for extracting knowledge from webpages.
- The user interface is friendlier and more streamlined.
Read the full interview with Mayank Kejriwal.
Related research on combatting human trafficking and child pornography from the Computer Society Digital Library
Login may be required for full text.
- Crime data mining: a general framework and some examples
- NuDetective: A Forensic Tool to Help Combat Child Pornography through Automatic Nudity Detection
- A Novel Skin Tone Detection Algorithm for Contraband Image Analysis
- A Statistical Approach for Identifying Videos of Child Pornography at Crime Scenes
- Efficient Tagging of Remote Peers During Child Pornography Investigations
- Behavioural Evidence Analysis Applied to Digital Forensics: An Empirical Analysis of Child Pornography Cases Using P2P Networks
- Challenges of automating the detection of paedophile activity on the Internet
- Unintended Consequences: Digital Evidence in Our Legal System

About Lori Cameron
Lori Cameron is a Senior Writer for the IEEE Computer Society and currently writes regular features for Computer magazine, Computing Edge, and the Computing Now and Magazine Roundup websites. Contact her at l.cameron@computer.org. Follow her on LinkedIn.







