Introducing DataCenterHub: A Massive Repository of Information to Help Researchers Worldwide Organize, Explore, and Share
By Lori Cameron
 Scientists and researchers have a huge problem when it comes to accessing shared databases of research information—pure chaos.
Scientists and researchers have a huge problem when it comes to accessing shared databases of research information—pure chaos.
It’s a mess of poorly-organized information that often must be downloaded to be examined or is hidden in zip files that can’t even be searched.
There must be a better way.
DataCenterHub shared a link to a humorous video that explains the type of problem they are trying to solve.
Fortunately, Purdue University and University of Nebraska researchers have developed a solution.
It’s called the DataCenterHub—a massive repository that will house research data from countless disciplines, from the humanities to science to computers and engineering. Their primary goals are to make it comprehensive, seamless, and easy to search.
“Our contribution to this field is a unique, comprehensive discipline-neutral representation for research data that encompasses both structured data and repository files. DataCenterHub provides a simple structure and feature-rich web platform for dataset upload, sharing, and discovery,” say the authors of “A Cyberplatform for Sharing Scientific Research Data at DataCenterHub” (login may be required for full text) in Computing in Science & Engineering.
One illustration of how the DataCenterHub works uses data from the Nepal earthquake of 2015. Below is an interface screenshot showing a variety of data sets included in one seamless visual that allows researchers to investigate infrastructure resilience and disaster preparedness.
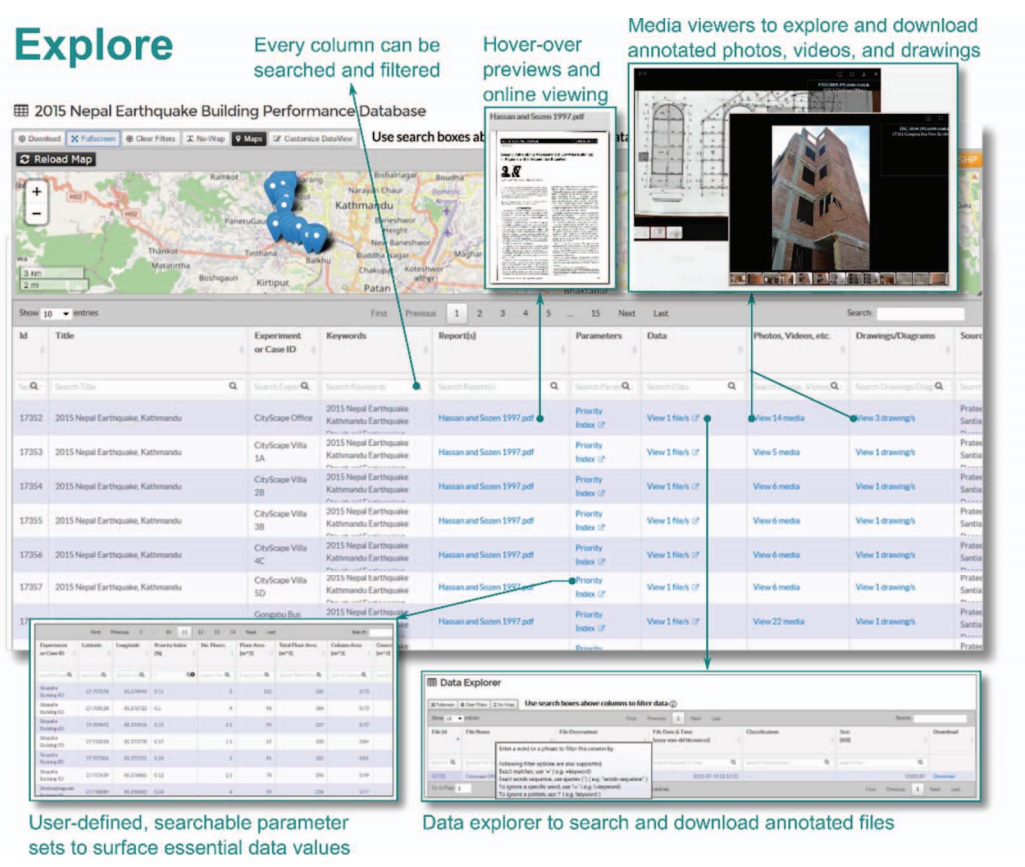
The interface shows building information such as photos, videos, drawings, and reports, a map with markers that display metadata, and key building vulnerability parameters that are auto-linked to building coordinates. DataCenterHub generates a merged view of heterogeneous data types for browsing and searching datasets.
One of the most powerful features of the data viewer is just how highly customizable it is.

“Datasets are organized by experiments, with a simple common structure for metadata, file collections, and key parameters. Researchers associate annotations, reports, media, measurements, observations, and outcomes to each experiment so that the relationship between an experiment and its data is clearly understood and the data can be accessed quickly and easily for search and exploration,” the authors explain.
In terms of reach, the DataCenterHub project is highly ambitious with the goal of becoming the go-to place for extensive, well-organized, easily-accessible research. There is no telling how much this will accelerate discovery and innovation in science and technology.
"DataCenterHub provides an alternative to existing discipline-neutral solutions, with the goal of helping as many researchers as possible classify and share their data and files for discovery and exploration. Nearly 50,000 experiments, 8,000,000 files, and 30 Tbytes of data have been contributed at DataCenterHub. Our extensible architecture allows new features to be added as needed, and our platform continues to evolve and adapt to an increasingly diverse community of users," the authors say.
Related research on data centers in the Computer Society Digital Library:
- Data Center Peak Power Management with Energy Storage Devices
- Design and Operational Analysis of a Green Data Center
- Data Center Energy Demand: What Got Us Here Won't Get Us There
- Thermal Time Shifting: Decreasing Data Center Cooling Costs with Phase-Change Materials
- BEEP: Balancing Energy, Redundancy, and Performance in Fat-Tree Data Center Networks

About Lori Cameron
Lori Cameron is a Senior Writer for the IEEE Computer Society and currently writes regular features for Computer magazine, Computing Edge, and the Computing Now and Magazine Roundup websites. Contact her at l.cameron@computer.org. Follow her on LinkedIn.







